
RAG & Datenintegration
Eigene Daten in die KI bringen.
Standard-KI kennt Ihr Unternehmen nicht. Mit RAG und Embedding-Technologie geben Sie der KI Zugriff auf Ihr Firmenwissen – sicher und kontrolliert.
Standard-KI kennt Ihr Unternehmen nicht. Mit RAG und Embedding-Technologie geben Sie der KI Zugriff auf Ihr Firmenwissen – sicher und kontrolliert.
Sprachmodelle wie Llama oder Mistral wurden auf öffentlichen Texten trainiert. Ihr internes Wiki, Ihre Produktdokumentation, Ihre Kundenhistorie, HR-Richtlinien und Projektdaten – all das ist der KI völlig unbekannt. Ohne diese Informationen sind Antworten zu generisch, um im Arbeitsalltag wirklich nützlich zu sein.
RAG (Retrieval-Augmented Generation) löst dieses Problem: Bevor die KI antwortet, durchsucht sie Ihre eigenen Daten nach relevanten Informationen und nutzt ausschließlich dieses verifizierte Firmenwissen als Kontext. Das Ergebnis: präzise Antworten mit Quellenangabe – ohne teures Nachtrainieren des Modells.
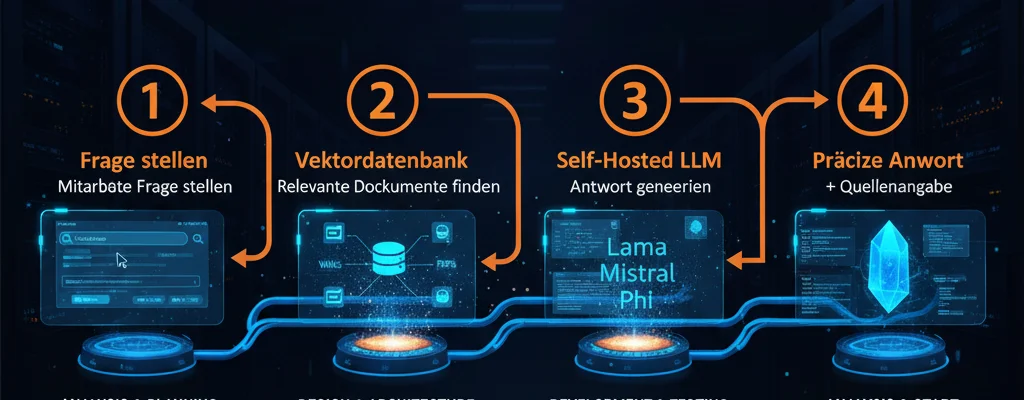
 01
01
 02
02
 03
03
 04
04
 05
05
Wir integrieren Ihre vorhandenen Systeme als Wissensbasis für die KI. Jede Quelle wird automatisch indiziert und über die Vektordatenbank semantisch durchsuchbar gemacht.
PDFs, Word-Dateien, Excel-Tabellen, Präsentationen – direkt indizierbar.
Confluence, Notion, MediaWiki, interne Handbücher – als Wissensbasis nutzbar.
Jira, Freshdesk, Zendesk – Support-Verlauf als Kontext für die KI nutzbar.
Dateien aus Nextcloud oder SMB-Shares automatisch in die Wissensbasis einbinden.
Strukturierte Daten aus ERP, CRM oder eigenen Datenbanken für die KI zugänglich machen.
E-Mail-Verläufe und Kalendereinträge als Kontext – z.B. für Support-Assistenten oder automatisierte Terminzusammenfassungen.
Reine Vektorsuche versteht den Kontext hinter einer Frage gut, stößt aber bei exakten Begriffen wie Artikelnummern, Fehlercodes oder juristischen Paragrafen an ihre Grenzen.
Deshalb setzen wir auf Hybrid Search: Die Kombination aus semantischer Vektorsuche und klassischer Keyword-Suche sorgt dafür, dass sowohl inhaltlicher Kontext als auch exakte Fachbegriffe zuverlässig gefunden werden.
Versteht Bedeutung und Zusammenhänge. Findet Antworten auch bei anderer Wortwahl.
Trifft exakte Begriffe: Produktcodes, Paragrafennummern, Eigennamen.
Sortiert die kombinierten Ergebnisse nach Relevanz – für maximale Präzision.
Jede Antwort referenziert die Originalquelle – nachvollziehbar und auditierbar.
Mitarbeiter stellen Fragen an die interne Wissensdatenbank – die KI findet und erklärt die Antwort.
→ Use Case ansehenDie KI schlägt Antworten auf Basis echter vergangener Tickets vor – schnellere Bearbeitung, weniger Rückfragen.
→ Use Case ansehenProduktinfos, Preislisten und Kundendaten als Kontext – die KI beantwortet Kundenanfragen präzise und konsistent.
Sprechen Sie mit uns – wir zeigen wie Ihre Wissensbasis aufgebaut werden kann.
Direkter Kontakt – ohne Umwege. Wir melden uns innerhalb eines Werktages.